






01“具身智能”机器人是人工智能终极形态
近期英伟达创始人CEO黄仁勋强调“具身智能”的重大价值。
黄仁勋在ITF Wold2023半导体大会上表示,人工智能的下一个浪潮是具身智能(Embodied AI),即能理解、推理、并与物理世界互动的智能系统,比如机器人、自动驾驶汽车,甚至聊天机器人,他们都能很好的理解物理世界。同时,黄仁勋公布 Nividia VIMA,一个多模态具身视觉语言模型。据介绍,VIMA 可以通过视觉执行任务,也可以通过文本提示来做任务,比如重新排列这些方块以与场景匹配;它能明白概念,采取适当行动,他可以在演示中学习,并且将行为控制在合理范畴内。
什么是具身智能?具身智能意味着什么?
具身智能”的机器人是人工智能的终极形态。
1950年,图灵在他的论文一《Computing Machinery and Intelligence》中首次提出了具身智能的概念。具身智能(Embodied AI)指的是,有身体并支持物理交的智能体,如智能服务机器人、自动驾驶汽车等,具身智能机器人指的是,像人一样能够与环境交互感知、自助规划、决策、行动、执行任务的机器人。
它包含人工智能领域几乎所有的技术,包括机器视觉、自然语言理解、认知和推理、机器人学、博弈伦理、机器学习等,横跨多个学科方向,是人工智能的集大成者。
现有机器人难以适应现实世界,是因为其学习模式为“旁观型学习方式”。
目前大部分深度学习模型训练使用的数据来自于互联网(Internat AI)而非现实世界第一人称视角只能学习到数据中心的固定模式,但无法在真实世界中直接学习,因此也无法适应真实世界。现实当中的人类是通过对现实世界的观察、互动、反馈等学习,大脑中的部分认知依赖物理身体与世界持续不断的交互,因此学习到越来越多的技能来适应环境。
具身智能是通往通用人工智能的关键钥匙,赋予机器人实践学习的能力。
斯坦福大学的李飞飞教授称“具身的含义不是身体本身,而是与环境交互以及在环境中做事的整体需求和功能。”上海交通大学的卢策吾教授通过猫学习走路来做出形象比喻:“如图中的猫样,主动猫是具身的智能,它可以在环境中自由行动,从而学习行走的能力。被动猫只能被动的观察世界,最终失去了行走能力。”
实践性学习方法与旁观型学方法的不同点在于,实践性学习是机器人像人一样,通过物理身体与环境的互动来学习,可以主动感知或者执行任务的方法来感知世界,对世界进行建模,增强对世界的认知和锻炼行能力。
具身智能的现实应用存在诸多难点,涉及到多学科知识。
拆解具身智能的应用过程当人要求机器人完成某一项任务,机器人要经过的步骤包括:能够听懂人类语言 分解任务规划子任务移动中识别物体 与环境交互 最终完成相应任务。这个过程涉及到自然语言理解、逻辑推理、机器视觉、运动控制、机器学习、运动规划、机械控制等。因此要实现完全的具身智能,依然有很长的一段路要走。
02 谷歌、微软、UCBerkeley等走在技术前沿
具身智能已成为全球学术和企业的重要的研究方向。
今年的 IROS(机器人领域顶级学术会议)将具身智能作为重要主题。目前谷歌、微软等技术团队、众多顶尖研究院所和高校已探索具身智能的发展落地。参考申万TMT 团队的《跨模态:更多应用场景出现,中国公司得到更大机会》、《Meta 发布 SAM 分割模型,或成 CV大模型第一步》,我们对最新的机器人算法模型进行梳理:
谷歌:视觉语言大模型 PaLM-E
2023年3月6日,来自谷歌和德国林工业大学的一组人工智能研究人员公布了史上最大视觉语言模型 PaLM-E( Pathways Language Model with Embodied)。
PaLM 包括了 40B 语言模型与 22B 视觉 ViT(Vison Transformer)模型,最终参数量达 562E。PaLM-E本身是个多模态的大模型不仅能理解文本,还能理解图片(ViT)可以理解图片中的语义信息。ViT将大模型能力泛化至CV领域,赋予大模型视觉能力。
两相结合,PaLM-E 模型具备多模态能力,能观察物理实体世界的信息,由大模型进行分析理解,再将决策结果反馈至物理世界,由此沟通物理和虚拟两个世界。
亮点在于多模态大模型应用于人机交互领域。
1)发现参数扩大有助于提升人机交互中的语言能力:语言模型越大,在视觉语言与机器人任务的训练中,保持的语言能力就越强,5620 亿参数的 PaLM-E 几乎保持了它所有的语言能力。
2)对于机器人的长跨度、长周期任务,以往通常需要人工协助, PaLM-E 通过自主学习全部完成,如下图左。
3)展示了模型的泛化能力,研究人员要求机器人将“绿色色块推到乌龟旁边”的指令,即便机器人之前没有见过这只乌龟摆,也能完成任务。
同时 PaLM-E 通过分析来自机器人摄像头的数据来实现对高级命令的执行,而无需对场景进行预处理。这消除了人类对数据进行预处理或注释的需要,并允许更自主的机器人控制。
Meta : SAM 分割模型
2023年4月6日,Meta 推出一个AI模型 Segment Anything Model(SAM分割一切模型),能够根据文本指令等方式实现图像分割。SAM 任务目的:零样本( zero-shot)或者简单 prompt 下,就对任意图片进行精细分割。
SAM 证明,多种多样的分割任务是可以被一个通用大模型涵盖的。SAM 做到的分割切并不是 CV大模型的终点,我们期待一个模型可以无监督完成分割、检测、识别、跟踪等所有 CV 任务,届时视觉大模型应用会得到极大发展。
微软: ChatGPT for Robotics
在Microsoft Research 的 ChatGPT for Robotics 文章中,研究者使用 ChatGPT生成机器人的高层控制代码,从而可以通过自然语言和ChatGPT交流,使用 ChatGPT来控制机械臂、无人机、移动机器人等机器人。
目前的机器人的应用基础是代码,工程师需要经常编写代码和规范来控制机器人的行为,这个过程缓慢、昂贵且低效,使用场景有限。ChatGPT 带来一种新的机器人应用范例通过大型语言模型(LLM)将人的语言快速转换为代码。在这种情境下,人们不需要学习复杂的编程语言或机器人系统的详细信息,就可以控制机器人来完成各种任务,更轻松的与机器人互动。
目前实验已经能够通过给 ChatGPT的对话框输入指令,让其控制机器人在房间中找到“健康饮料”“有糖和红色标志的东西”(可乐),以及一面供无人机自拍的镜子。
伯克利的 LM-Nav 模型
UC Berkeley、波兰华沙大学联合谷歌机器人团队发表论文《LM-Nav:具有大型预训练语言、视觉和动作模型的机器人导航系统》,该模型结合了三种预训练模型,从而无需用户注释即可执行自然语言指令。
其中,大语言模型(LLM)用于完成自然语言处理的任务;视觉和语言模型(VLM )将图像和文本信息进行关联,即用户指令和机器人视觉感知的外部环境进行关联;视觉导航模型(VNM)用于从其观察到的信息中直接进行导航将图像和将要执行的任务按时间进行关联
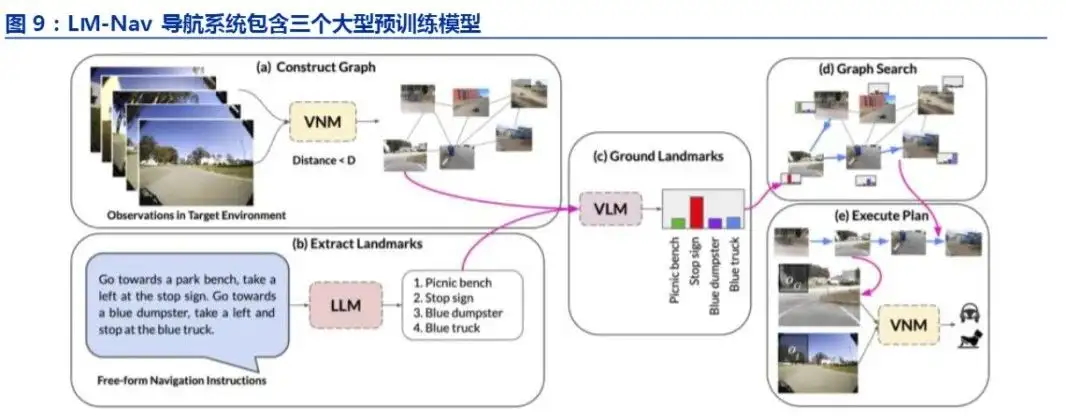
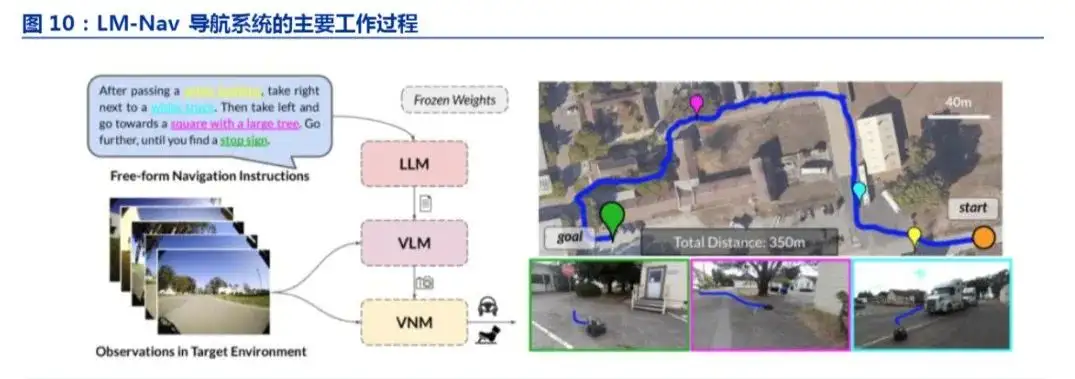
03 具身智能落地应用机器人的方向和节奏?
随着具身智能的发展,跨模态大模型应用于机器人的案例不断出现,各行各业、各种形态的机器人有望持续涌现。
技术层面,我们认为具身智能最先解决的可能是人机交互问题,现有GPT等多模态大语言模型已经开始应用,让机器人听得懂人的语言指令,其次解决机器人的决策能力,即分析、推理、判断等能力,深度学习、神经网络、强化学习等将是机器人重要的学习手段,最后解决机器人的执行能力,让机器人处理现实中的复杂任务。
考虑到降本周期、应用难度、市场接受度等因素,我们认为最先应用的落地的可能是价格不敏感的、应用难度较低、市场接受度较高的机器人类型,排序如下:
商用服务机器人:
接待机器人、迎宾机器人、服务机器人、导购机器人等,商用场景的价格敏感度较低,应用场景简单,市场接受度高,或成为最先落地的场景;
特定行业的功能型机器人:
电力巡检类操作类机器人、轨道交通的检修机器人、矿山里的机器人、农业机器人、建筑机器人等,此类环境危险恶劣,对机器人的需求度高价格不敏感;
家庭服务机器人:
家务机器人、陪伴机器人等,toC 场景的价格敏感度较高,并且家庭是非结构化环境,外部环境和任务较为复杂,因此落地进度或慢于toB 场景;
通用型人形机器人:
人形机器人具有最完善的具身智能,能够集成各项人工智能技术,也是最为通用的机器人类型,潜在应用空间最为广阔,或成为机器人的终极形态。






- 1