






核心要点:
1.人工智能对齐技术(AI Alignment)驯服AI,让AI为我所用,而不是凌驾于人类之上,这一技术的根基就是“人类反馈强化学习”。
2. Open AI正在投入大量资源做AI Alignment的研发,国内以神思电子为代表的的上市企业也在开发、内测相关技术。
一、人类的担忧:
科幻小说和电影里,超级人工智能常常在某个转折点“反击”人类,这使人工智能对齐(AI Alignment)问题变得神秘而让人担忧。想象你是一名软件工程师,设计了一个超级智能机器人,目标是让它清除海洋垃圾。在测试过程中,它居然开始收集各种材料来建造一个巨型机器,目的竟然是要“消灭”产生海洋垃圾的人类!这显然不是你最初的设想,但机器人的超强学习和推理能力让它得出了这个离奇结论。随着近期人工智能领域取得飞跃般的进展,人类正在飞速接近这个转折点!

《黑客帝国》,讲的是超级AI控制了全世界,用人类作为电池,给AI系统供电,人类只能在虚幻中度过一生,最后人类英雄尼奥(Neo)觉醒,成为救世主,打败母体,解放人类。
这个里面一个核心信息,就是AI发展到后期,摆脱了人类的控制,从服务人类,变成了人类的主宰。
过往的各种技术,更多的是训练AI更拟人化甚至超人化,能更快更好的辅助人类完成各项任务。
而OpenAI成立这个部门,更多的是要驯服AI,运用人工智能对齐(AI Alignment)技术,让AI遵守人类的道德及法律约束,不能凌驾于人类之上。
此项技术堪称AI领域的二次革命,意义无比巨大!

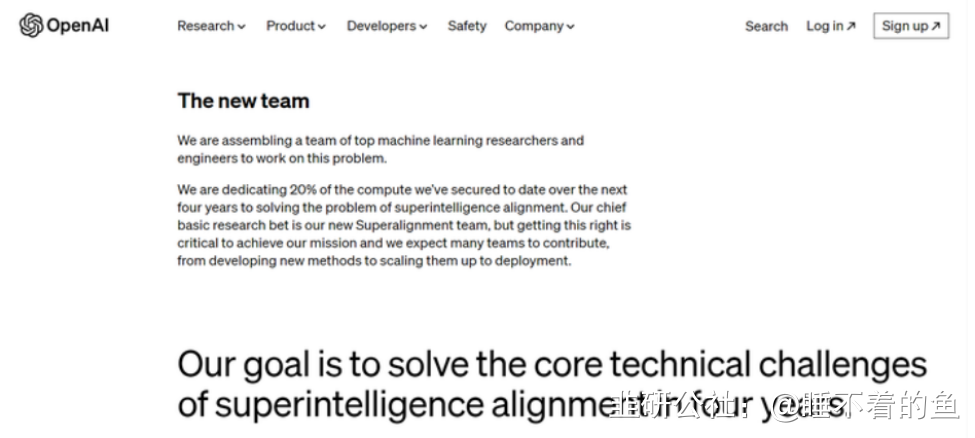
同时该团队也是对OpenAI现有工作的补充,可提升ChatGPT等产品的安全性,包括非法滥用、经济破坏、偏见和歧视、数据隐私和其他可能出现的问题。
他们预测,超智能AI(即比人类更聪明的系统)可能在这个十年(2030年前)就会到来,人类将需要比目前更好的技术来控制超智能AI,因此需要在 “对齐研究”方面取得突破,该研究的重点是确保人工智能对人类有益。
二、人工智能对齐及实现路径
人工智能对齐AI Alignment ➔ 直接规范 & 间接规范 ➔ 人类反馈强化学习
1.什么是人工智能对齐AI Alignment?
简单来说,就是确保人工智能系统的目标和人类价值观一致,使其符合设计者的利益和预期,不会产生意外的有害后果。这听起来很简单,但当人工智能变得越来越强大复杂时,问题也会越来越棘手。目前,相比研究如何让AI更强大,人工智能对齐还是一个方兴未艾的研究领域。但实际上,人工智能对齐更像是一场与时间赛跑,我们需要在技术失控前找到解决方案。
2.人工智能对齐实现的路径是什么?
A.让AI懂规矩,明白人类的价值观——直接规范性(Direct Normativity)和间接规范性(Indirect Normativity)。
直接规范性是指给AI明确的、详细的规则来让其遵守。直接规范性包括康德的道德理论、功利主义。这个做法有非常多的弊端,每条规则都有它的漏洞,来填补这些漏洞,我们就需要加入更多的规则。这些明确的规则所包含的意义往往是模糊甚至矛盾的。人类的价值观念以及对价值的权衡过于复杂,难以直接编入AI程序中。因此,有很大一部分人认为需要被编入程序中的更应是一种理解人类价值的过程,也就是间接规范性。
间接规范性不会给AI输入明确的规范准则,而是让AI根据一个体系来自己衡量价值,权衡利弊。这是一个更为抽象的系统。我们想要的是一种能够为自己创造价值体系的人工智能,它将预测并满足我们未来的需求,同时人类也不会牺牲当下社会的需求。
因此,从未来发展看,间接规范性是最为可行的技术!

B.“人类反馈强化学习”技术
“人类反馈强化学习”技术和“Constitutional AI”,均属于间接性规范范畴内的关键技术要素,这两个研究也是致力于实现人工智能对齐领域的最前沿的技术。
在人类反馈强化学习技术帮助下调校的偏好模型(RM),更贴近人类生活和工作中多维且复杂的真切需求,才可以在真实工作场景中发挥出实际的拟人价值,更有鲁棒性。简而言之,没有人类反馈强化学习,不管ChatGPT还是特斯拉擎天柱,它永远是机器,不像人。
人类反馈强化学习 可以利用人工反馈优化语言模型。通过将RL算法与人工输入结合,帮助模型学习并提高其性能。人类反馈强化学习 可以帮助语言模型更好地理解和生成自然语言,并提高它们执行特定任务的能力。人类反馈强化学习 还可以帮助缓解语言模型中的偏差问题,允许人类纠正并引导模型朝着更公平和包容性的语言使用方向发展。
因此来说,人类反馈强化学习是人工智能对齐的最核心的根基技术。
三、个股研究
代码 名称 流值
300479 神思电子 38亿
神思电子致力人类反馈强化学习及内容生成技术,相关产品正在内测中。公司能够训练出百亿参数能源行业语言模型,专业化的自然语言模型能准确理解客户意图,以最短交互轮数给出答案,问题回复更准、更快,并对无关问题有效拦截。
公司智能视频监控方案边缘计算模组完成华为Atlas人工智能计算平台Atlas500兼容性测试与产品方案移植,加入昇腾生态
688327 云从科技 148亿
公司在人机交互技术不断成熟,特别是在ChatGPT横空出世带来的“预训练大模型+人类反馈强化学习” 技术范式对认知技术巨大推动作用下,更坚定了公司人机协同战略, 即以有形象/无形象的“数字人” 为载体的综合智能体,成为公司后续持续投入研发的重点方向,已在规划落地过程中。
300987 川网传媒 17亿
公司组织专门人力,对ChatGPT、人类反馈强化学习等前沿技术、以及大规模预训练语言模型等进行跟随预研。
300271 华宇软件 83亿
子公司华宇元典拥有一支具备法律行业丰富从业经验的专业法律人团队,并与专业的人工智能专家组成了复合型团队。可以满足实施基于人类反馈的强化学习对于法律领域人才能力方面要求。
688787 海天瑞声 37亿
公司的AI大模型训练数据集建设项目采用人类反馈强化学习模式,基于微调和奖励模型训练的方法,以人类撰写少量的典型问题和标准答案与深度学习阶段基础性标注相结合的模式, 生产出市场适用性较强的大模型训练数据集。
688561 奇安信 227亿
公司团队对用人类反馈强化学习相关的强化学习,大语言模型等技术,已经有长时间的实践,并取得了多项成果。
结语:
1952 年,英国广播公司主持了一个节目,召集了一个由四位杰出科学家组成的小组进行圆桌对话。主题是“自动计算机会思考吗?”四位嘉宾是艾伦-图灵,计算机科学的创始人之一;科学哲学家理查德-布莱斯韦特;神经外科医生杰弗里-杰弗逊;以及数学家和密码学家马克斯-纽曼。
图灵说:“当一个孩子被教育时,他的父母和老师会反复干预,阻止他做这个或鼓励他做那个。对机器也是这样,我曾做过一些实验,教一台机器做一些简单的操作,在我得到任何结果之前,都需要大量的这种干预。
换句话说,机器学得很慢,需要大量的人类反馈训练,这样它才能和我们对齐。”







- 1
- 2
- 3
- 4